
Đọc/Tải dữ liệu
Đôi khi chúng ta có những ứng dụng phải chịu tải lớn. Để giải quyết vấn đề này, chúng tôi trình bày ba kỹ thuật khác nhau mà chúng ta có thể triển khai.
Kỹ thuật đặt bộ nhớ cache
Kỹ thuật đặt bộ nhớ cache lưu trữ dữ liệu được yêu cầu thường xuyên hoặc kết quả của các phép tính tính toán phức tạp trong bộ nhớ tạm thời. Dữ liệu được lưu trữ
trong bộ nhớ cache cần được thay đổi theo tính chất của ứng dụng và để cập nhật chúng, kỹ thuật vô hiệu hóa và xóa bộ nhớ cache có thể được sử dụng để duy trì tính nhất quán của dữ liệu. Điều này có thể được đạt được thông qua phương pháp hết hạn thời gian sống (TTL) của bộ nhớ cache hoặc các phương pháp khác phụ thuộc vào các mô hình đặt bộ nhớ cache được sử dụng.
Có thể sử dụng các mô hình đặt bộ nhớ cache khác nhau như một chiến lược để triển khai các giải pháp đặt bộ nhớ cache. Đặt bộ nhớ cache "Caching aside" hỗ trợ đọc nặng và hoạt động ngay cả khi bộ nhớ cache gặp sự cố. Đọc thông qua ("Read-through") và Ghi thông qua ("Write-through") được sử dụng cùng nhau. Chúng là các lựa chọn tuyệt vời cho công việc đọc nặng, nhưng sự cố với bộ nhớ cache sẽ dẫn đến sự cố hệ thống. Ghi trở lại ("Write-back") hữu ích cho công việc ghi nặng, và nó được sử dụng bởi các triển khai của các hệ quản trị cơ sở dữ liệu khác nhau.
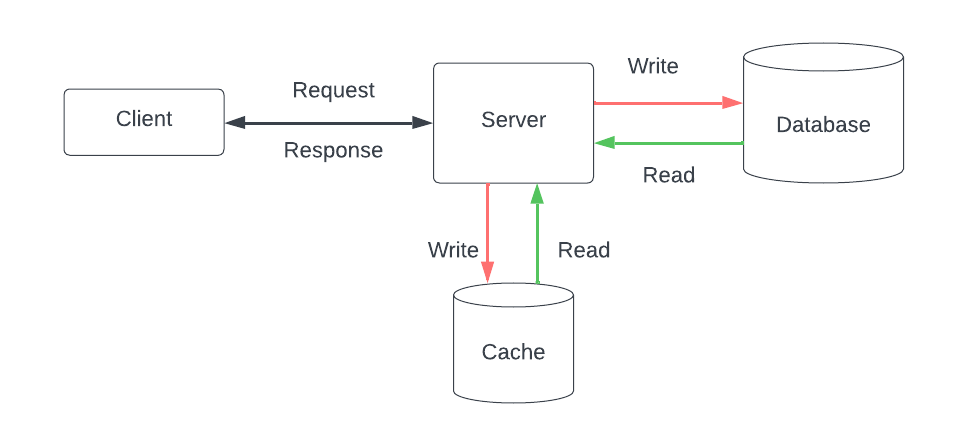
Tùy thuộc vào yêu cầu như đọc nặng, ghi nặng hoặc sự kết hợp của cả hai, chúng ta có thể quyết định sử dụng mô hình nào một cách linh hoạt để đảm bảo khả năng chịu đựng sự cố với cache hoặc cơ sở dữ liệu.
Replication
Sao chép hoạt động bằng cách có một cơ sở dữ liệu được gọi là cơ sở dữ liệu chính, nơi mọi yêu cầu ghi đều được chuyển đến. Ngoài ra, chúng ta tạo ra một bản sao chính xác của cơ sở dữ liệu chính đó là các nút sao chép mới được gọi là nút phụ, chỉ đảm nhận xử lý các yêu cầu đọc. Cơ sở dữ liệu chính liên tục cung cấp dữ liệu mới nhất cho các nút sao chép, đảm bảo tính nhất quán của thông tin giữa tất cả các nút trong cụm.
Sao chép là một chiến lược tuyệt vời để xử lý khả năng chịu lỗi và duy trì định lý CAP và khả năng mở rộng của hệ thống. Giả sử một trong các nút gặp sự cố, chúng ta vẫn tiếp tục phục vụ vì chúng ta có dữ liệu giống nhau được sao chép trong các nút khác. Ngoài ra, trong một cụm, một nút có thể tiếp quản và trở thành cơ sở dữ liệu chính trong trường hợp mất mát của nút chính. Sao chép cũng giúp giảm độ trễ trong ứng dụng, vì chúng ta có thể triển khai cơ sở dữ liệu và sao chép dữ liệu trên các vùng khác nhau như CDN và nó có thể được truy cập dễ dàng bởi người dùng địa phương.
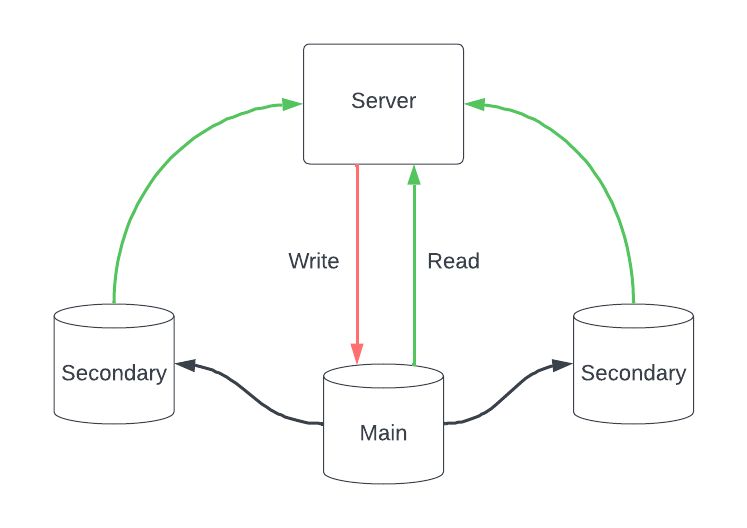
Đồng bộ và Bất đồng bộ
Ngoài những lợi ích đó, việc duy trì tính nhất quán trong nút sao chép trở nên phức tạp khi số lượng nút tăng lên. Vấn đề này có thể được giải quyết bằng cách sử dụng chiến lược sao chép đồng bộ hoặc bất đồng bộ tùy thuộc vào yêu cầu.
Chiến lược đồng bộ có lợi thế là thời gian chậm gấp đôi bằng không và dữ liệu luôn được nhất quán, nhưng nhược điểm là hiệu suất bị ảnh hưởng vì cần phải chờ đến khi tất cả các bản sao được cập nhật và được xác nhận bởi người phát hành. Trong khi đó, trong chiến lược bất đồng bộ, việc ghi trở nên nhanh hơn vì nút chính không chờ xác nhận, nhưng đặt ra vấn đề về trạng thái không nhất quán nếu một bản sao không cập nhật được giá trị.
Hãy nhớ rằng không có giải pháp tổng quát, chiến lược tốt nhất phụ thuộc vào nhu cầu của chúng ta. Phải có sự đánh đổi giữa tính nhất quán, khả dụng hoặc phân vùng (Định lý CAP). Định lý CAP khẳng định rằng chúng ta chỉ có thể đảm bảo hai trong số ba yếu tố này cùng một lúc.
Đánh chỉ mục (indexing)
Các chỉ mục được sử dụng để định vị và truy cập dữ liệu nhanh chóng, cải thiện hiệu suất hoạt động của cơ sở dữ liệu. Một bảng cơ sở dữ liệu có thể có một hoặc nhiều chỉ mục liên kết với nó.
Chỉ mục cải thiện hiệu suất truy vấn bằng cách tăng tốc việc truy xuất dữ liệu, nó cải thiện hiệu suất truy cập dữ liệu bằng cách giảm số lần I/O cần thiết để lấy dữ liệu. Chỉ mục tối ưu hóa việc sắp xếp dữ liệu vì cơ sở dữ liệu không cần phải sắp xếp toàn bộ bảng mà chỉ cần sắp xếp các hàng có liên quan. Chỉ mục duy trì tính nhất quán của dữ liệu ngay cả khi lượng dữ liệu tăng lên. Ngoài ra, chỉ mục đảm bảo tính toàn vẹn của cơ sở dữ liệu, ngăn việc lưu trữ dữ liệu trùng lặp.
Nhược điểm của việc tạo chỉ mục là nó cần nhiều không gian lưu trữ, làm tăng kích thước cơ sở dữ liệu. Nó cũng làm tăng công việc bảo trì với việc thêm, xóa và sửa đổi trong bảng. Chỉ mục có thể làm giảm hiệu suất trong việc chèn và cập nhật dữ liệu. Việc lựa chọn chỉ mục có thể khó khăn đối với một truy vấn hoặc ứng dụng cụ thể.
Ghi dữ liệu
Đối với các ứng dụng có nhiều hoạt động ghi dữ liệu vào cơ sở dữ liệu, với người dùng liên tục thêm dữ liệu mới, chúng ta có các chiến lược như sharding và NoSQL.
Trong sharding, chúng ta chia nhỏ cơ sở dữ liệu thành nhiều phần nhỏ hơn gọi là shard. Mỗi shard có thể được đặt trên một máy chủ riêng biệt, và mỗi máy chủ quản lý một phần dữ liệu. Điều này giúp phân tải tải lên nhiều máy chủ và tăng khả năng mở rộng của hệ thống. Các ghi được phân tán trên các shard khác nhau, giúp tăng tốc độ ghi dữ liệu. Tuy nhiên, việc truy vấn và thao tác cập nhật đồng thời trên các shard khác nhau có thể phức tạp và đòi hỏi sự đồng bộ giữa chúng.
NoSQL (Not Only SQL) là một hệ thống cơ sở dữ liệu phi quan hệ, được thiết kế để xử lý các tải lớn và linh hoạt hơn so với cơ sở dữ liệu quan hệ truyền thống. NoSQL cho phép chúng ta lưu trữ và truy xuất dữ liệu một cách phi cấu trúc, linh hoạt và phân tán trên nhiều máy chủ. Điều này giúp tăng tốc việc ghi dữ liệu và khả năng mở rộng của hệ thống. Tuy nhiên, NoSQL có thể không phù hợp cho các ứng dụng đòi hỏi tính nhất quán cao hoặc các truy vấn phức tạp.
Cả sharding và NoSQL đều cung cấp các chiến lược để xử lý việc ghi dữ liệu nhiều vào cơ sở dữ liệu và đảm bảo hiệu suất và khả năng mở rộng của hệ thống.
Sharding
Sharding hoặc phân vùng dữ liệu cho phép tách dữ liệu của cơ sở dữ liệu lớn thành các phần nhỏ hơn, nhanh hơn và dễ quản lý hơn, chia cơ sở dữ liệu thành nhiều cơ sở dữ liệu chính khác nhau. Có hai loại phân vùng, phân vùng theo chiều dọc và phân vùng theo chiều ngang.
Phân vùng dữ liệu có lợi thế về tối ưu hóa truy vấn, mang lại hiệu suất tốt hơn và giảm độ trễ. Nó cho phép khả năng có dữ liệu của người dùng ở các vị trí khác nhau có thể truy cập nhanh hơn cho người dùng ở các khu vực cụ thể. Ngoài ra, nó có lợi thế tránh được một điểm lỗi duy nhất.
Một trong những nhược điểm của phân vùng là quá tải phân vùng trong trường hợp chúng ta không phân phối dữ liệu qua các phân vùng một cách chính xác. Tùy thuộc vào chiến lược chúng ta chọn, chúng ta có thể kết thúc với một số phân vùng có nhiều dữ liệu và một số phân vùng có ít dữ liệu, và truy vấn trên phân vùng lớn đó có thể trở nên chậm hơn. Một nhược điểm khác là quay trở lại và khôi phục trạng thái trước của chiến lược không phân vùng sau khi nó đã được triển khai và dữ liệu được chia thành các cơ sở dữ liệu khác nhau.
Việc áp dụng phân vùng có thể là logic hoặc vật lý. Phân vùng logic xảy ra khi chúng ta có một tập con dữ liệu khác nhau trong cùng một máy vật lý, và phân vùng vật lý có thể có nhiều hơn một tập con phân vùng trên một máy vật lý.
Để phân chia dữ liệu, chúng ta có thể lựa chọn giữa phân chia theo thuật toán hoặc phân chia động. Có các thuật toán và kỹ thuật phân vùng động khác nhau như phân vùng dựa trên khóa, phân vùng dựa trên phạm vi và phân vùng dựa trên thư mục là những phương pháp được sử dụng nhiều nhất.
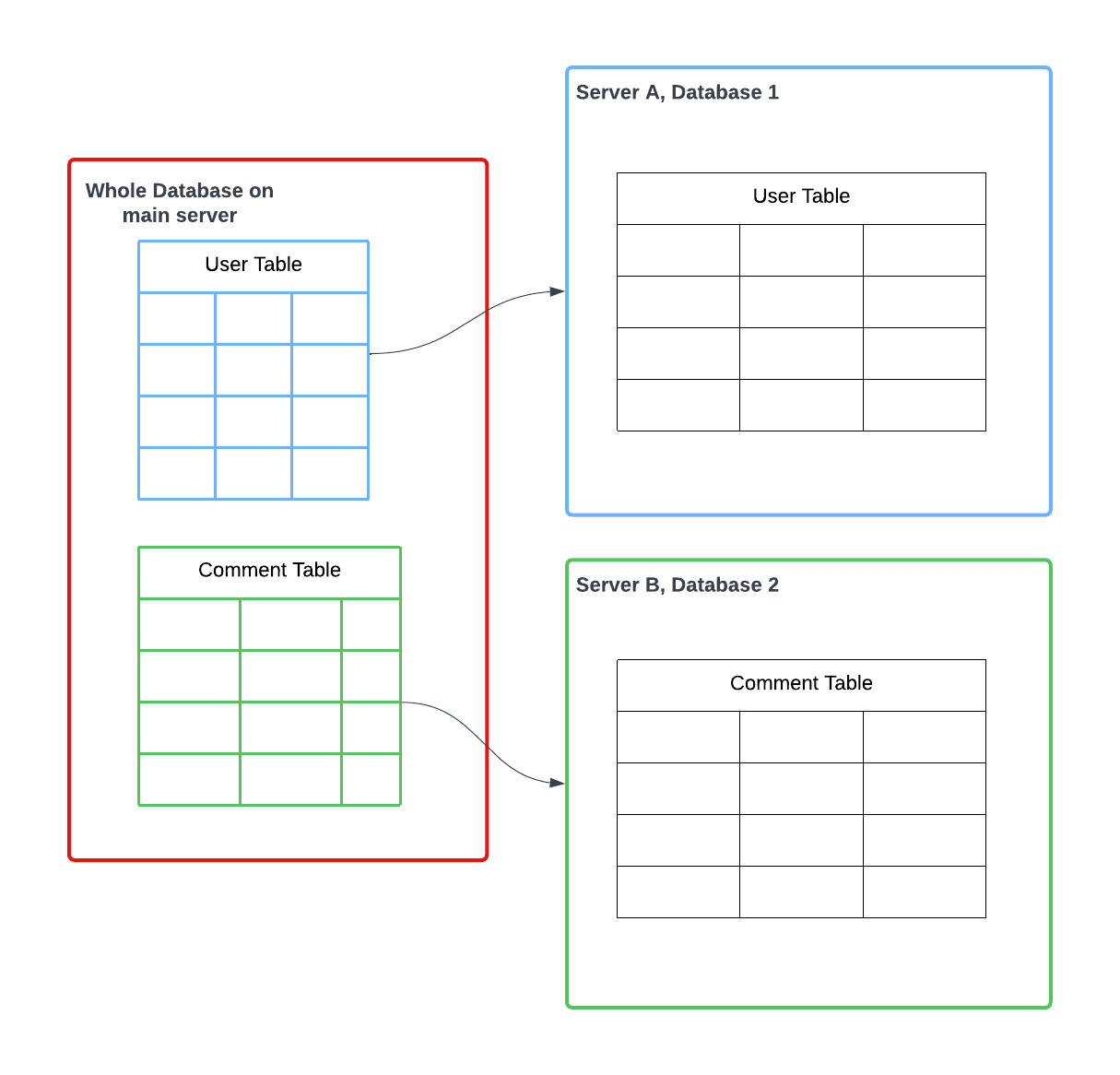
Phân vùng theo chiều dọc
Đối với phân vùng theo chiều dọc, chúng ta lấy mỗi bảng và đặt chúng trên các máy chủ khác nhau. Ví dụ như bảng người dùng, bảng nhật ký hoặc bảng bình luận, mỗi bảng trên các máy chủ khác nhau. Phân vùng theo chiều dọc hiệu quả khi các truy vấn thường chỉ trả về một tập con của các cột dữ liệu. Ví dụ, nếu một số truy vấn chỉ yêu cầu tên, và các truy vấn khác chỉ yêu cầu địa chỉ, thì tên và địa chỉ có thể được phân vùng trên các máy chủ riêng biệt.
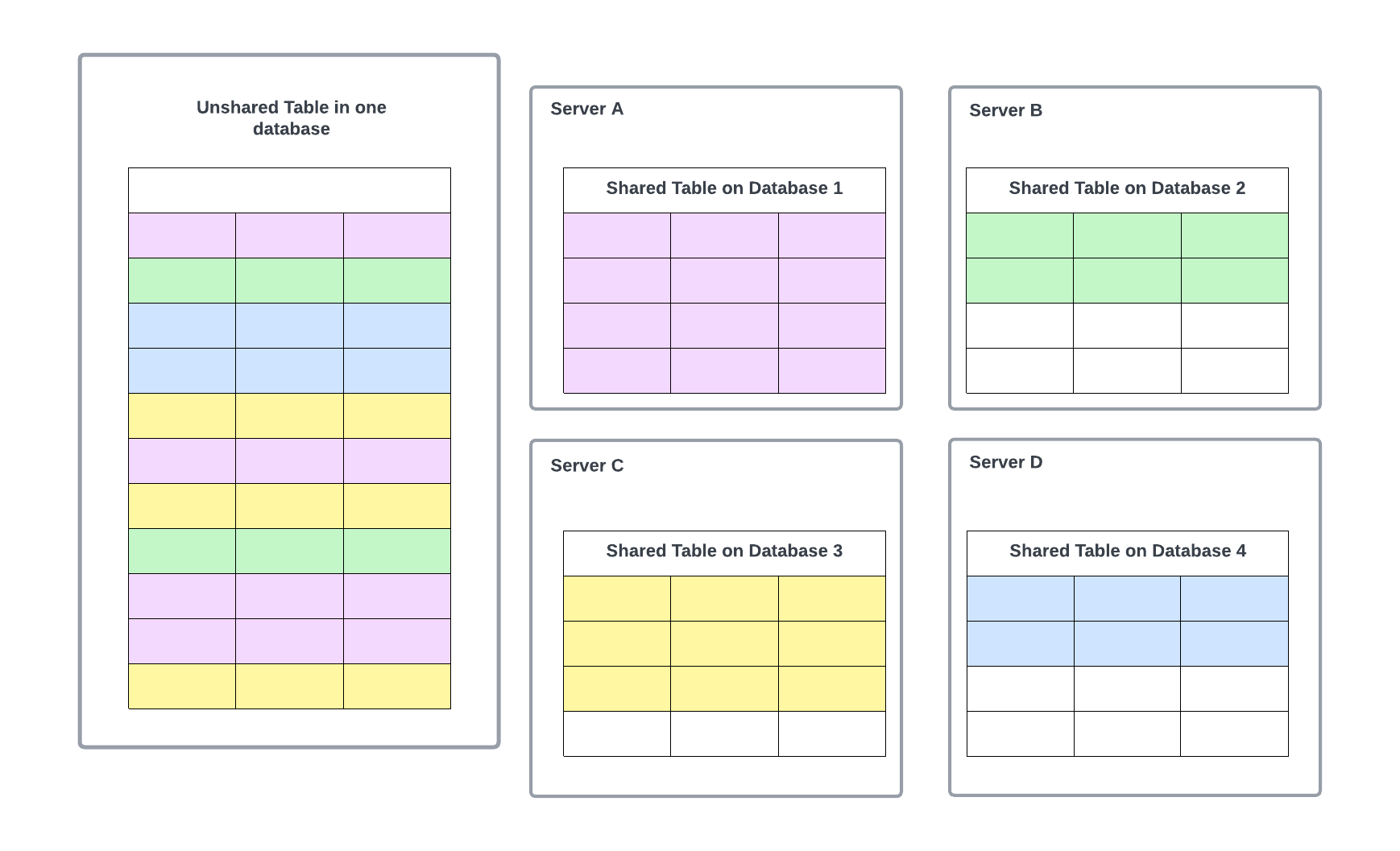
Phân vùng theo chiều ngang
Trong trường hợp chúng ta có một bảng duy nhất trở nên rất lớn, chúng ta áp dụng phân vùng theo chiều ngang. Chúng ta lấy một bảng duy nhất và chia một phần dữ liệu liên quan thành nhiều máy chủ. Phân vùng theo chiều ngang hiệu quả khi các truy vấn thường chỉ trả về một tập con các hàng dữ liệu thường được nhóm lại. Ví dụ, các truy vấn lọc dữ liệu dựa trên khoảng ngày ngắn là lý tưởng cho phân vùng theo chiều ngang, vì khoảng ngày sẽ giới hạn việc truy vấn chỉ đến một tập con các máy chủ.
NoSQL
NoSQL không phải là một cơ sở dữ liệu quan hệ và về cơ bản là một cặp khóa-giá trị. Mô hình cặp khóa-giá trị có khả năng mở rộng một cách tự nhiên trên nhiều máy chủ khác nhau. NoSQL được phân loại thành bốn danh mục chính: Hướng cột lưu trữ dữ liệu dưới dạng các gia đình cột, Cơ sở dữ liệu đồ thị lưu trữ dữ liệu dưới dạng các nút và cạnh, Cửa hàng khóa-giá trị lưu trữ dữ liệu dưới dạng cặp khóa-giá trị và Cửa hàng tài liệu lưu trữ dữ liệu dưới dạng tài liệu bán cấu trúc.
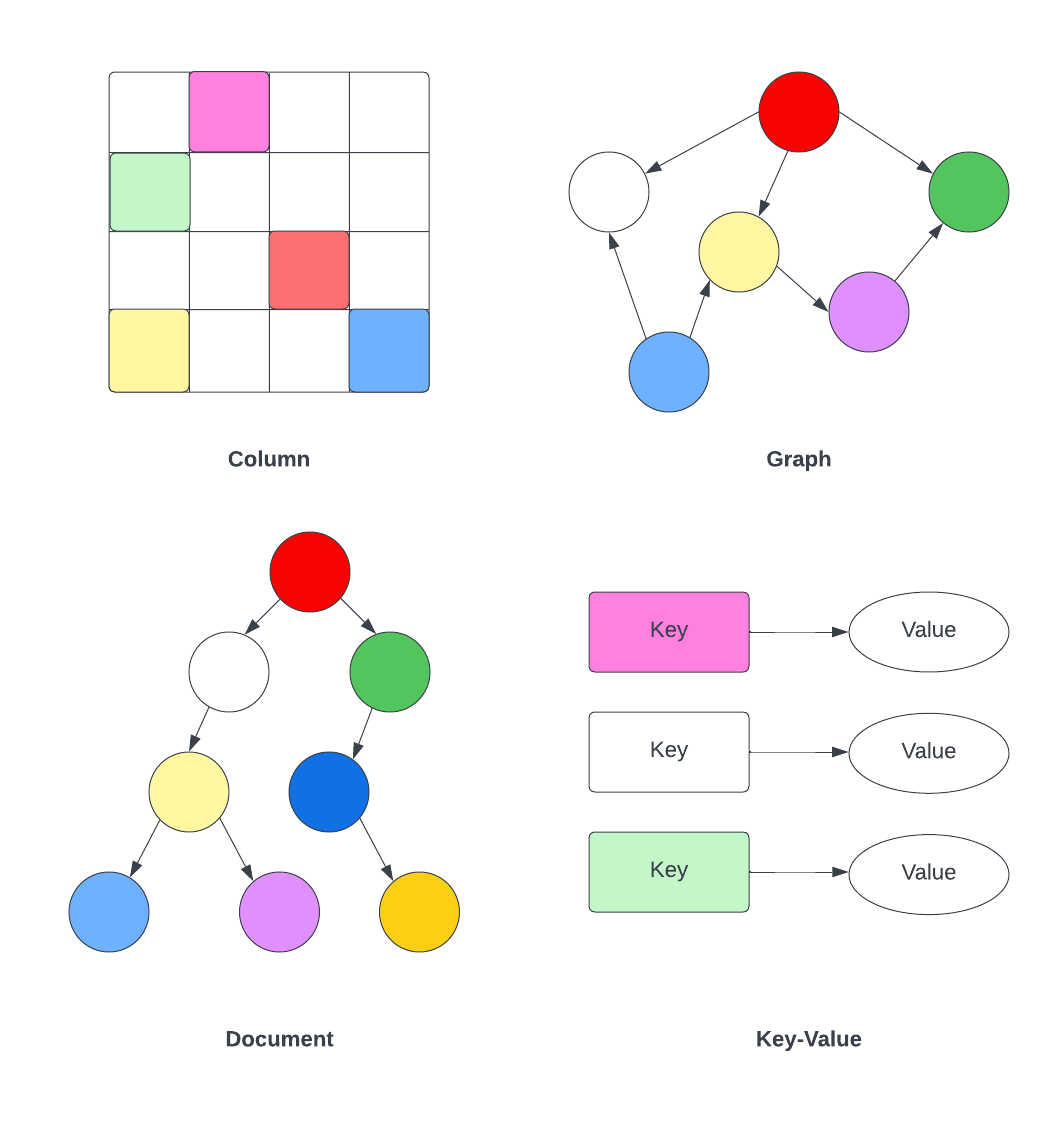
NoSQL cho phép mô hình schema linh hoạt có thể chứa các thay đổi mà không cần thay đổi schema. Nó cung cấp khả năng mở rộng theo chiều ngang vì nó được thiết kế để mở rộng bằng cách thêm nhiều nút vào một cụm cơ sở dữ liệu. Nó cũng được thiết kế để đảm bảo tính sẵn có cao để xử lý tự động các lỗi nút và sao chép dữ liệu qua nhiều nút trong cụm.
Cơ sở dữ liệu phi quan hệ này cung cấp một số lợi ích so với cơ sở dữ liệu quan hệ, chẳng hạn như khả năng mở rộng, linh hoạt và hiệu quả về chi phí. Tuy nhiên, chúng cũng có một số hạn chế, chẳng hạn như thiếu tiêu chuẩn hóa, thiếu tuân thủ ACID và thiếu hỗ trợ cho các truy vấn phức tạp.



